
隨著科學技術水平的不斷提高,人們對機械產品的性能、壽命和可靠性的要求也不斷提高,對機器及儀器零件的加工精度要求愈來愈高,各種高硬度材料的使用也日益增加。此外由于精密鑄造與精密鍛造工藝的進步,許多零件可以不經過車削、銑削直接由毛坯磨制成成品,從而使得磨削加工獲得了越來越廣泛的應用和迅速發展[1]。在磨削加工中,表面完整性可以用來衡量磨削加工表面質量的好壞,目前對于零件表面完整性的要求也越來越高,它主要包含表面紋理指標與表面層物理力學性能指標兩類[2]。而工件表面粗糙度是表面完整性指標中極為重要的一個參數,也是決定磨削加工質量的重要因素之一。粗糙度的大小對工件使用性能有很大的影響,表面粗糙度越小,零件的耐磨性、耐疲勞性、耐腐蝕性相應就越好,并且可提高零件裝配時的配合精度。
目前國內外將智能算法運用于表面粗糙度預測的應用研究越來越多,但是其側重點不一樣。河海大學的林崗等人使用模糊自適應BP 算法建立了影響表面粗糙度參數與工件表面粗糙度之間的關系模型,依據給定的數據樣本對模型進行訓練,將訓練好的網絡進行實際的表面粗糙度預測。湖南大學的李波等人建立了基于BP 神經網絡的表面粗糙度聲發射預測模型,以聲發射信號有效值、FFT 峰值和標準差作為網絡輸入,對高效深磨陶瓷工件表面粗糙度進行預測。吉林大學的李曉梅等對影響磨削表面粗糙度的12個因素進行了討論,并選擇其中7 個主要因素建立了模糊網絡粗糙度預測模型。AL-AHRNARIF對BP 神經網絡模型和線性回歸模型進行了對比,結果顯示神經網絡模型比線性回歸模型更有優勢。NALBANT等研究了切削參數及刀具材料對車削表面粗糙度的影響,并建立了3 層BP 神經網絡,對加工過程的表面粗糙度進行預測。
從以往的研究中可以看出: 人工神經網絡預測模型具有良好的預測精度,并且不同于回歸分析,它不需要一開始就建立輸入參數和輸出參數的數學模型。在以往的分析研究中,由于BP 人工神經網絡具有很好的函數逼近性能、結構簡單、可操作性好,故所用的模型多為BP 網絡模型。但需要指出的是: BP 網絡存在收斂速度慢、網絡學習和記憶具有不穩定性、容易陷入局部最小值等缺點,在實際應用中,需要對BP 網絡算法進行改進。文中主要利用學習速度快、泛化能力和逼近性能更強的徑向基函數RBF 神經網絡來對磨削表面粗糙度進行預測研究。
1 磨削表面粗糙度智能預測的基本框架
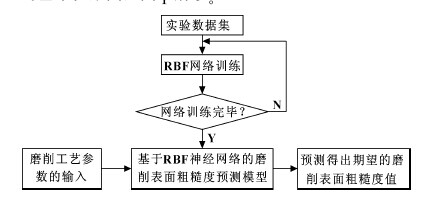
首先根據已有的經驗數據集或者實驗數據訓練神經網絡,應保證在網絡訓練完畢之后使其已經具備了計算磨削參數的能力。由于RBF 神經網絡具有很好的函數逼近性能,通過一定數量的磨削實驗數據進行網絡訓練,可以擬合出在一定磨削加工條件下的磨削表面粗糙度的預測模型。將對磨削表面粗糙度影響較大的磨削工藝參數作為輸入參數輸入網絡中,通過已經建立好的RBF 神經網絡預測模型得出期望輸出的磨削表面粗糙度值。具體的磨削表面粗糙度智能預測的基本框架圖如圖1 所示。
2 RBF 神經網絡基本理論
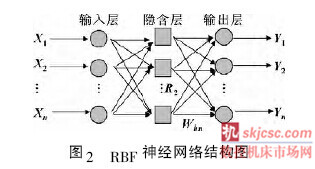
2. 1 RBF 神經網絡結構
徑向基函數RBF 神經網絡是只有一個隱藏層的3層前饋神經網絡類型,其網絡結構可以表示為如圖2所示。在該網絡中,輸入層只起到傳輸信號的作用,輸出層和隱層的學習策略并不一樣。輸出層是調整線性權值,采用策略是線性優化,而隱層是對激活函數的參數進行調整,采用的策略是非線性優化。構成RBF 網絡的基本思路是用RBF 作為隱含單元的基構成隱含空間,這樣就可將輸入矢量直接映射到隱空間[9]。與其他前向網絡相比最大的不同在于: 隱層的轉換函數是局部響應的高斯函數,而以前的前向網絡的轉換函數都是全局響應函數。正是由于局部響應的特點,它能夠以任意精度逼近任意連續函數,并且具有全局逼近的特點,不存在陷入局部最小值問題,同時它具有良好的泛化能力,計算量小,學習速度也比一般其他算法要快。
2. 2 RBF 神經網絡的學習算法
在RBF 網絡的學習算法中,需要求解的主要參數有3 個: 基函數的中心、方差以及隱含層到輸出層的權值。依據徑向基函數中心選取方法的不同,RBF網絡的學習方法也有所不同,如有隨機選取中心法、自組織選取中心法、有監督選取中心法和正交最小二乘法等。目前用得比較廣泛的是自組織選取中心法,其學習算法的具體步驟[11]如下:

3 磨削表面粗糙度預測模型的建立
3. 1 影響表面粗糙度的因素
磨削加工是一個復雜過程,受眾多的輸入因素影響,磨削結果通常缺乏一定的必然規律。同樣,影響磨削加工表面粗糙度的因素也有很多,有工件材料的化學成分、工件的尺寸大小、金相組織、砂輪特性、修整狀況、磨損程度、砂輪線速度、工件速度、磨削深度、材料去除率與磨削液等[2]。歸納起來主要受3 方面的影響,即工件材料信息、砂輪信息和加工條件信息。由于在實驗過程中工件材料信息及砂輪信息一般都是給定的,所以文中主要考慮加工條件信息,即砂輪線速度、工件速度、磨削深度、材料去除率這4 個主要影響因素對工件表面粗糙度的影響。
3. 2 樣本數據的獲取
3. 2. 1 磨削實驗條件
實驗用機床。實驗在MGKS1332 /H-SB-04 型高速外圓磨床( 如圖3) 上進行。砂輪架部件采用閉式靜壓導軌形式,并采用伺服電機和精密絲杠的傳動結構; 砂輪軸系采用高速滾動軸承和內裝式電機結構,砂輪主軸裝有SBS 動平衡儀。頭架采用伺服電機和同步帶傳動結構,頭架主軸系統為滾動軸承形式的成熟結構。床身為整體鑄件,具有良好抗振性和熱穩定性。

磨削試件材料為20CrMnTi,表面滲碳淬火,單邊滲碳層深度為1. 5 mm,磨削外圓直徑為插入80 mm,外圓軸向尺寸為18 mm。磨削砂輪為99VG3A1-400-22-5,最高砂輪線速度為150 m/s,陶瓷結合劑。測量儀器。此實驗采用JB-4C 精密粗糙度儀對擦凈后的磨削試件的表面粗糙度進行測試。在給定的取樣長度內,在垂直于磨痕的方向上測量被加工表面的粗糙度Ra,在每種工況條件下選擇3 個不同位置測量,并取其平均值。
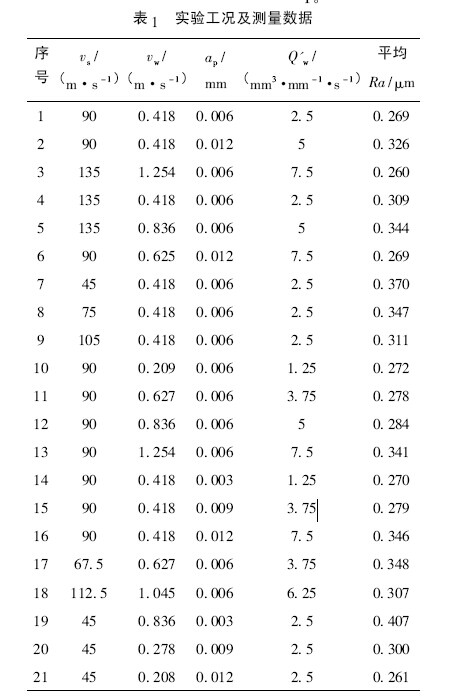
3. 2. 2 實驗工況及測量數據
每次實驗前,先要對砂輪進行動平衡,使用在線動平衡儀( SBS) 按照相應的砂輪線速度進行平衡,當平衡量達到0. 03 μm 后開始實驗。實驗采用乳化液冷卻,切入外圓磨削。每完成5 組實驗,就利用金剛石滾輪對砂輪進行修整,在每一組磨削實驗前均要進行修銳,以保證砂輪狀態一致性。在相同的工裝條件下,磨削工藝參數的變化將直接影響工件表面質量,合理的工藝參數能夠保證加工目標的實現,具體的磨削工況及表面粗糙度測量值見表1。
3. 3 數據的歸一化處理
網絡訓練和執行時,必須對輸入輸出參數中的非數值數據進行量化、數值數據進行歸一化處理,這樣有利于RBF 神經網絡在訓練過程中收斂速度更快,效果更佳。
對實驗數據( 砂輪線速度、工件速度、磨削深度、材料去除率、表面粗糙度) 進行歸一化處理,將數據處理為區間[0,1] 之間的數據。歸一化方法有很多形式,這里采用式( 3) 進行歸一化處理。
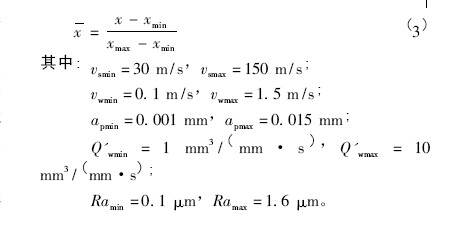
3. 4 RBF 網絡的設計
3. 4. 1 輸入輸出參數的設定
在建立RBF 神經網絡模型時,將影響工件表面粗糙度的主要因素作為網絡輸入層參數,輸出層參數則為表面粗糙度。確定網絡模型各層參數如下:輸入樣本為4 個磨削參數,輸出樣本為1 個,RBF網絡的隱含層神經元則由訓練過程決定。網絡的目標誤差設定為0. 000 1,神經元最大個數設定為50,兩次顯示之間所添加的神經元數目設定為1。故此神經網絡結構的確定重點是隱層神經元個數的確定。
3. 4. 2 隱層神經元個數的確定
在RBF 神經網絡模型的建立中,隱含層神經元的個數是影響網絡預測性能的重要因素。確定的有效方法是在RBF 網絡的訓練過程中,通過選取不同寬度系數SPREAD 的值對網絡進行訓練,通過訓練得到的各個網絡的預報精度及訓練次數,來確定網絡最佳的隱含層神經元數。
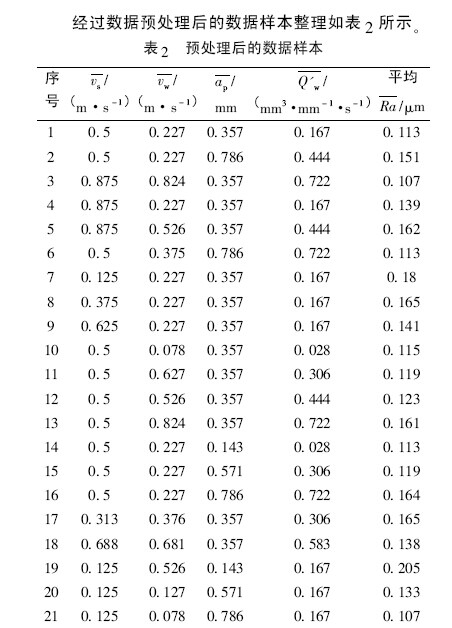
通過循環算法設計了一個寬度系數值SPREAD可變的訓練算法,通過誤差對比,確定最佳的隱層神經元個數。其中的訓練樣本來源于表2 中1—16 組實驗數據。不同SPREAD 值條件下的訓練情況如表3 所示。

在SPREAD 值為2 時,雖然其訓練次數多了1 次,但其所能達到的預報精度遠遠高于其他4 組值( 訓練結果如圖4 所示) 。因此該網絡寬度系數值SPREAD 選為2,此時網絡的訓練次數為15 次,網絡模型的隱層神經元個數為15 個,故RBF 網絡結構可確定為4—15—1。

4 預測結果及分析
為了驗證此神經網絡模型的預測效果,抽取表2中17—21 組數據進行預測,其預測結果如表4 所示。
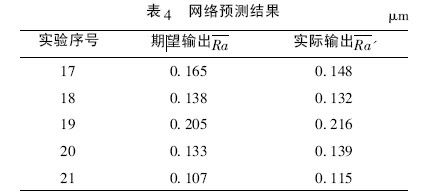
從表4 可以看出: 期望輸出和實際輸出的數值差值還是在可以接受的范圍之內,預測準確率在85%以上。這說明此磨削表面粗糙度智能預測模型在實際工作中也可發揮作用,體現了其實用價值。
5 結論
(1) 通過MATLAB 實現了RBF 神經網絡的表面粗糙度的預測模型,解決了傳統方法對非線性預測精度不高和復雜建模的問題。
(2) 在RBF 神經網絡模型的建立中,隱含層神經元的個數是影響網絡預測性能的重要因素。采用循環算法,選取不同寬度系數SPREAD 的值對網絡進行訓練,通過訓練得出各個網絡的預報精度及訓練次數,以此來確定網絡最佳的隱含層神經元數。
(3) 從提高智能預測模型預測準確率的角度出發,還可以加入更多的樣本數據用以反復的訓練,這樣訓練出來的網絡的精確度更高,模型預測出的結果更接近實際情況。
(4) 該預測模型的準確率可以達到85% 以上,相對誤差遠小于使用經驗公式分析時的相對誤差,對磨削表面粗糙度的預測研究具有一定的參考和應用價值。
如果您有機床行業、企業相關新聞稿件發表,或進行資訊合作,歡迎聯系本網編輯部, 郵箱:skjcsc@vip.sina.com








